水處理智慧運維平臺供應商家
全鏈路監控是智慧運維平臺的主要功能之一,通過在應用系統、網絡設備、數據庫等關鍵節點部署采集探針,實現從用戶請求發起至業務響應完成的全流程數據捕獲。平臺采用分布式追蹤技術,可準確定位跨服務調用中的性能瓶頸,例如識別出數據庫慢查詢、網絡延遲等問題對業務的影響程度;同時結合時序數據庫存儲監控指標,支持秒級數據聚合與歷史趨勢分析,讓運維人員能夠直觀掌握系統運行狀態。相較于傳統單點監控,全鏈路監控實現了 “問題可追溯、根源可定位、風險可預判”,大幅提升了故障排查效率。微服務架構支持新增功能靈活接入。水處理智慧運維平臺供應商家
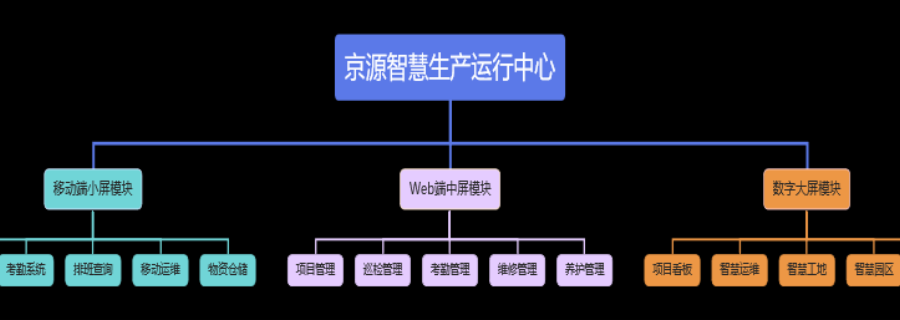
AI與ML是智慧運維平臺的“大腦”。在異常檢測方面,監督學習算法可以利用已標記的故障數據訓練模型,識別已知的異常模式。然而,更具價值的是無監督或半監督學習算法,它們能夠從海量正常行為數據中學習,自動構建動態基線,并對偏離該基線的微小異常進行告警,這對于發現此前未知的、潛在的“沉默故障”至關重要。此外,深度學習模型能夠處理更復雜的時序數據和非結構化數據(如文本日志),發現更深層次、更隱蔽的關聯關系,將異常檢測的準確率和覆蓋范圍提升到一個全新的水平。智慧園區智慧運維平臺哪里有賣的支持現場巡檢結果實時上傳。

在運維工作中,存在大量重復、規則明確的跨系統操作任務,例如創建工單、查詢賬號狀態、跨平臺數據錄入等。智慧運維平臺可以集成RPA技術,創建“數字員工”來替代人工完成這些任務。例如,當檢測到某個應用頻繁崩潰時,平臺可觸發RPA機器人自動在故障管理系統(ITSM)中創建工單,并填充相關的錯誤日志和關聯信息。這進一步延伸了自動化的邊界,將人類從低價值的重復勞動中徹底解放。智慧運維平臺的容量管理,利用預測算法和趨勢分析,實現從“靜態預估”到“動態優化”的轉變。平臺不僅能預測未來資源需求,還能通過分析應用的實際資源使用模式,識別出過度配置的資源(如CPU常年利用率低于10%的虛擬機),并提出資源回收或縮容建議。在容器化環境中,它能持續優化Kubernetes的資源請求(Request)和限制(Limit)配置,在保障應用穩定的前提下,比較大化集群的資源利用密度,實現明顯的降本增效。
安全與運維的融合(SecOps)是智慧運維的重要戰場。平臺通過統一的數據底座,將安全事件(如入侵檢測告警、漏洞掃描報告)與運維數據(如異常進程、非常規登錄、性能異常)進行關聯分析。例如,一個服務器突然出現CPU占用率高,同時伴有對外網的大量流量傳輸,這很可能是被入侵挖礦的跡象。通過將安全分析融入日常運維監控,實現了對“灰色安全事件”(即不直接觸發安全規則,但表現出運維異常的安全威脅)的早期發現,推動了DevSecOps文化中“安全左移”和“持續監控”的實踐落地。科學決策優化調度提升效率。
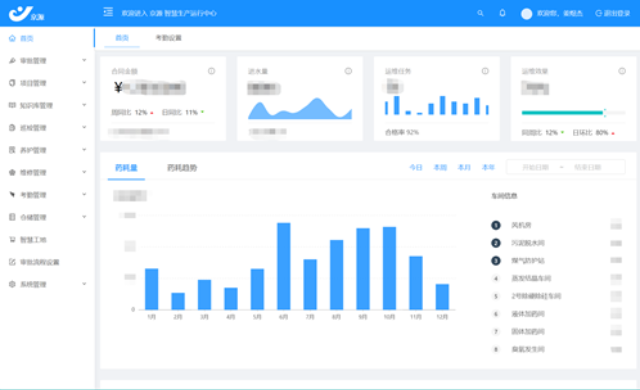
智慧運維平臺是管理海量、分散的物聯網設備的關鍵。平臺通過物聯網協議接收設備上傳的狀態數據、遙測數據和事件,利用大數據和AI能力,實現對設備群的集中監控、故障預測和遠程維護。例如,對于城市中的智能路燈,平臺可以監控其開關狀態、亮度、能耗,預測燈具壽命并自動生成維修工單;對于工業傳感器,可以分析其數據流,預警設備異常。這種大規模、自動化的設備運維能力,是智慧城市、工業互聯網等場景得以落地運營的重要保障。數字大屏采用高清 LED 大屏幕呈現。海南智慧運維平臺聯系電話
圖形化動態化展示復雜水務數據。水處理智慧運維平臺供應商家
智慧運維平臺的上線不是終點,而是新一輪優化的起點。必須建立一個持續改進與運營的體系。這包括:定期回顧平臺產生的價值,通過關鍵指標(如MTTR降低率、告警減少量、自動化成功率)來衡量投資回報;收集平臺用戶(運維、開發人員)的反饋,不斷優化用戶體驗和功能;緊跟技術發展,適時引入新的AI算法和數據分析方法。一個良好的智慧運維平臺本身就應該是一個能夠自我演進、自我優化的生命體,其運營過程就是其價值持續放大的過程。水處理智慧運維平臺供應商家
- 水處理智慧運維平臺供應商家 2025-12-19
- 廣東智慧運維平臺公司 2025-12-19
- 甘肅智慧運維平臺服務廠家 2025-12-19
- 設備維護智慧運維平臺銷售 2025-12-19
- 鹽城個性化 企業智能知識庫 2025-12-19
- 定制智慧運維平臺聯系電話 2025-12-19
- 宿遷企業智能知識庫市價 2025-12-19
- 生態園區智慧運維平臺聯系人 2025-12-19
- 智慧園區智慧運維平臺生產商 2025-12-19
- 重慶智能預警智慧運維平臺 2025-12-19
- 虎丘區新型節能活性炭檢測供應 2025-12-20
- 安徽無污染過濾材料 2025-12-20
- 黃浦區品牌自動清洗系統供應商家 2025-12-20
- 上海工廠用凈水器維修質量商家 2025-12-20
- 廣東專業河道治理企業 2025-12-20
- 湖南傳遞窗降價 2025-12-20
- 嘉興品牌污水處理生物填料銷售廠 2025-12-20
- 常州品牌污水處理藥劑批發價格 2025-12-20
- 威海環保數字化平臺定制 2025-12-20
- 湖北血漿分離中空纖維膜供應 2025-12-20