河南智慧導讀價格
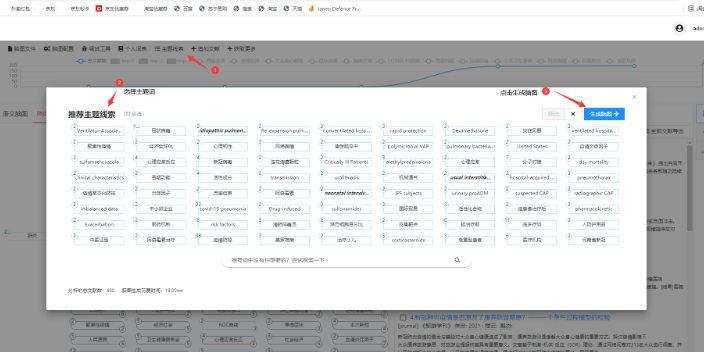
智慧閱讀服務內容方面的研究覆蓋讀物供給智慧化、輔助閱讀智慧化和閱讀推廣智慧化等主題。有關讀物供給智慧化的研究包括移動讀物供給[9]、虛擬現實讀物供給[10-11]及個性化閱讀推薦[12-13]等方面,讀物涉及文本、視頻、音頻、圖像、數據等多種形式,如視聽閱讀內容[14]、有聲讀物[15]、歷史人物數據[16]、在線可視化數據[17]等。輔助閱讀智慧化研究方面,K.LO等探討“人工智能和人機交互的***進展能否為智能、交互式和可訪問的閱讀界面提供動力”[18]。基于眼動追蹤和大語言模型技術的智能AI閱讀助手SARA通過實時提供個性化幫助來增強閱讀體驗[19]。同時,對支持閱讀過程的新技術平臺需求正在增長[18]。有關閱讀推廣智慧化的研究包含服務流程[20]、模式框架及實踐[21]等方面。另外,少數學者調查高校圖書館智能服務水平并分析阻礙因素[22]。在語義關聯矩陣中,由起始入口詞選擇任意某個興趣點,系統會找出兩者之間潛在的5條隱性知識鏈路。河南智慧導讀價格

信息通信技術(ICT)作為技術基座,構成信息信任系統的基礎設施。技術哲學視域下,信息通信技術不僅改變了信息供需關系,還重構了認知勞動分工。智慧閱讀依賴信息的搜索和過濾技術,它們是解決信息冗余的重要手段。不同技術對讀者的要求也不盡相同—信息搜索的質量很大程度上依賴讀者對所需信息描述的準確程度;信息的過濾則是信息供給方提供的一種服務,它從讀者的歷史行為和數據中篩選讀者感興趣的內容,**終表現為信息推薦。信息過濾的技術包括數據挖掘、知識圖譜、聚類算法、協同過濾、序列推薦、機器學習、深度學習、復雜網絡等。技術的迭代顯示機器從服從和執行人類指令過渡到有監督的學習,現在又往無監督的方向演進。算法黑箱給生產者和消費者帶來一定程度的信任剝奪,基于對信息發布主體的信任受到沖擊。安徽品牌智慧導讀尤其是網絡技術、數字存儲和傳輸技術等的普及,數字圖書館應運而生。
基于數據分析的結果,構建個性化的推薦算法模型。這些模型可以根據用戶的個人特征和閱讀歷史,預測用戶可能感興趣的內容,并生成相應的推薦列表。推薦算法模型需要不斷地進行優化和調整,以適應用戶閱讀行為的變化和新的數據輸入。將生成的推薦結果以合適的方式展示給用戶,如通過推送通知、郵件、APP界面等方式。同時,根據用戶的反饋和行為數據,對推薦結果進行實時調整和優化,以提高推薦的準確性和用戶滿意度。在整個過程中,需要嚴格遵守相關法律法規,保護用戶的隱私和數據安全。對用戶數據進行加密存儲和傳輸,確保只有經過授權的人員才能訪問和使用相關數據。
面向數智環境下圖書館數智服務的全要素精細感知、復雜資源有效融合、多服務高效協同等需求,結合IT規劃參考模型,系統分析智慧圖書館的前沿研究與實踐,充分融合智慧數據的演進范式及迭代模式,以數據治理體系為基礎、數智技術體系為賦能智慧數據流通轉化過程及圖書館數智服務流程,通過層次化、模塊化、組件化的方式,分人機交互層、數智服務層、業務層、數據存儲層、標準規范層、基礎設施層構建融合智慧數據的圖書館數智服務平臺。各高校圖 書館應加強未來學習中心試點建設,打造高標準智慧 化的學習新體系。
首先,智慧導讀系統會收集用戶在閱讀過程中的各種數據,包括但不限于用戶的閱讀時長、閱讀偏好、閱讀歷史、點擊行為、評論反饋等。這些數據可以通過用戶在平臺上的行為自動記錄,也可以通過用戶主動填寫問卷或設置偏好等方式獲取。收集到的原始數據可能包含噪聲、重復或無效信息,因此需要進行數據清洗和預處理。這一步包括去除重復數據、填充缺失值、轉換數據格式等操作,以便進行后續的數據挖掘工作。利用機器學習和數據分析技術,對用戶數據進行深度挖掘。這包括對用戶的閱讀習慣、興趣偏好、情感傾向等進行分析,發現用戶潛在的閱讀需求和興趣點。同時,通過對用戶數據的聚類、分類和關聯規則挖掘等,可以發現用戶群體之間的相似性和差異性,為后續的推薦算法提供依據。閱讀服務包括閱讀素養教育、讀物供給、輔助閱 讀等內容。互聯網智慧導讀
文本語義腦圖檢索系統通常會針對某一文獻內容特征進行單一維度的文獻聚類細分。河南智慧導讀價格
在技術迅速更迭下,國內外學者積極探索AIGC融入圖書館服務的應用場景。陸偉等探討以ChatGPT為**的大語言模型對信息資源建設、信息組織與檢索、信息治理等方面的影響[28]。趙楊等構建融合AIGC技術的智慧圖書館體系框架[29],儲節旺等從服務方式、服務內容、服務效果等三個方面分析AIGC對智慧圖書館服務的沖擊[30]。國外有學者指出基于ChatGPT的聊天機器人系統是傳統的基于知識庫的聊天機器人的可行替代方案[31],同時AI聊天機器人可能會對參考咨詢實踐、館藏開發以及元數據創建和轉換產生影響[32]。河南智慧導讀價格
- 方便科研學術助手數據分析 2025-12-21
- 哪些科研學術助手均價 2025-12-21
- 數字圖書館科研學術助手案例 2025-12-21
- 數字圖書館科研學術助手簡介 2025-12-21
- 質量科研學術助手服務 2025-12-21
- 質量科研學術助手大概價格多少 2025-12-20
- 信息科研學術助手服務 2025-12-20
- 提供科研學術助手成本 2025-12-20
- 圖書館科研學術助手聯系方式 2025-12-20
- 參考科研學術助手均價 2025-12-20
- 方便科研學術助手數據分析 2025-12-21
- 儀器測試金屬材料價格 2025-12-21
- 崇明區本地新媒體運營優勢 2025-12-21
- 會計財務軟件好用 2025-12-21
- 蘇州品牌數字內容制作服務供應 2025-12-21
- 上海常規PTI試驗粉塵 2025-12-21
- 海東品牌汽車銷售咨詢報價 2025-12-21
- 普陀區咨詢阻燃材料檢測供應 2025-12-21
- 山東精裝交付第三方巡檢價格 2025-12-21
- 杭州錢塘區集資詐騙刑事辯護懷孕 2025-12-21