楊浦區正規驗證模型價目
結構方程模型是基于變量的協方差矩陣來分析變量之間關系的一種統計方法,是多元數據分析的重要工具。很多心理、教育、社會等概念,均難以直接準確測量,這種變量稱為潛變量(latent variable),如智力、學習動機、家庭社會經濟地位等等。因此只能用一些外顯指標(observable indicators),去間接測量這些潛變量。傳統的統計方法不能有效處理這些潛變量,而結構方程模型則能同時處理潛變量及其指標。傳統的線性回歸分析容許因變量存在測量誤差,但是要假設自變量是沒有誤差的。交叉驗證:交叉驗證是一種更為穩健的驗證方法。楊浦區正規驗證模型價目
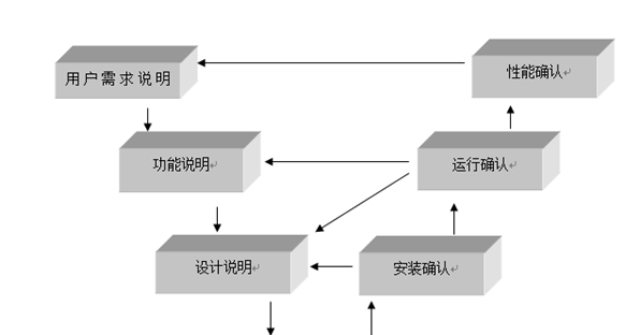
驗證模型是機器學習和統計建模中的一個重要步驟,旨在評估模型的性能和泛化能力。以下是一些常見的模型驗證方法:訓練集和測試集劃分:將數據集分為訓練集和測試集,通常按70%/30%或80%/20%的比例劃分。模型在訓練集上進行訓練,然后在測試集上評估性能。交叉驗證:K折交叉驗證:將數據集分為K個子集,模型在K-1個子集上訓練,并在剩下的一個子集上測試。這個過程重復K次,每次選擇不同的子集作為測試集,***取平均性能指標。留一交叉驗證(LOOCV):每次只留一個樣本作為測試集,其余樣本作為訓練集,適用于小數據集。徐匯區正規驗證模型要求如果你有特定的模型或數據集,可以提供更多信息,我可以給出更具體的建議。
用交叉驗證的目的是為了得到可靠穩定的模型。在建立PCR 或PLS 模型時,一個很重要的因素是取多少個主成分的問題。用cross validation 校驗每個主成分下的PRESS值,選擇PRESS值小的主成分數。或PRESS值不再變小時的主成分數。常用的精度測試方法主要是交叉驗證,例如10折交叉驗證(10-fold cross validation),將數據集分成十份,輪流將其中9份做訓練1份做驗證,10次的結果的均值作為對算法精度的估計,一般還需要進行多次10折交叉驗證求均值,例如:10次10折交叉驗證,以求更精確一點。
性能指標:分類問題:準確率、精確率、召回率、F1-score、ROC曲線、AUC等。回歸問題:均方誤差(MSE)、均方根誤差(RMSE)、平均***誤差(MAE)等。模型復雜度:通過學習曲線分析模型的訓練和驗證性能,判斷模型是否過擬合或欠擬合。超參數調優:使用網格搜索(Grid Search)或隨機搜索(Random Search)等方法優化模型的超參數。模型解釋性:評估模型的可解釋性,確保模型的決策過程可以被理解。如果可能,使用**的數據集進行驗證,以評估模型在不同數據分布下的表現。通過以上步驟,可以有效地驗證模型的性能,確保其在實際應用中的可靠性和有效性。回歸任務:均方誤差(MSE)、誤差(MAE)、R2等。

性能指標:根據任務的不同,選擇合適的性能指標進行評估。例如:分類任務:準確率、精確率、召回率、F1-score、ROC曲線和AUC值等。回歸任務:均方誤差(MSE)、均***誤差(MAE)、R2等。學習曲線:繪制學習曲線可以幫助理解模型在不同訓練集大小下的表現,幫助判斷模型是否過擬合或欠擬合。超參數調優:使用網格搜索(Grid Search)或隨機搜索(Random Search)等方法對模型的超參數進行調優,以找到比較好參數組合。模型比較:將不同模型的性能進行比較,選擇表現比較好的模型。外部驗證:如果可能,使用**的外部數據集對模型進行驗證,以評估其在真實場景中的表現。根據任務的不同,選擇合適的性能指標進行評估。嘉定區智能驗證模型供應
擬合度分析,類似于模型標定,校核觀測值和預測值的吻合程度。楊浦區正規驗證模型價目
驗證模型是機器學習過程中的一個關鍵步驟,旨在評估模型的性能,確保其在實際應用中的準確性和可靠性。驗證模型通常包括以下幾個步驟:數據準備:數據集劃分:將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調整模型參數(如超參數調優),測試集用于**終評估模型性能。數據預處理:包括數據清洗、特征選擇、特征縮放等,確保數據質量。模型訓練使用訓練數據集對模型進行訓練,得到初始模型。根據需要調整模型的參數和結構,以提高模型在訓練集上的性能。楊浦區正規驗證模型價目
上海優服優科模型科技有限公司匯集了大量的優秀人才,集企業奇思,創經濟奇跡,一群有夢想有朝氣的團隊不斷在前進的道路上開創新天地,繪畫新藍圖,在上海市等地區的商務服務中始終保持良好的信譽,信奉著“爭取每一個客戶不容易,失去每一個用戶很簡單”的理念,市場是企業的方向,質量是企業的生命,在公司有效方針的領導下,全體上下,團結一致,共同進退,**協力把各方面工作做得更好,努力開創工作的新局面,公司的新高度,未來上海優服優科模型科技供應和您一起奔向更美好的未來,即使現在有一點小小的成績,也不足以驕傲,過去的種種都已成為昨日我們只有總結經驗,才能繼續上路,讓我們一起點燃新的希望,放飛新的夢想!
- 嘉定區智能展示車加工便捷 2025-12-18
- 崇明區正規工程樣車試制平臺 2025-12-18
- 金山區直銷汽車設計開發優勢 2025-12-18
- 長寧區智能驗證模型平臺 2025-12-18
- 青浦區銷售驗證模型熱線 2025-12-18
- 上海智能汽車設計開發信息中心 2025-12-18
- 長寧區專用汽車設計開發供應 2025-12-18
- 楊浦區正規驗證模型價目 2025-12-18
- 浦東新區自動工程樣車試制供應 2025-12-18
- 靜安區自動驗證模型供應 2025-12-18
- 柱狀活性炭檢測焦糖脫色率 2025-12-18
- 泰州工廠保潔托管服務 2025-12-18
- 珠海勞務外包公司推薦 2025-12-18
- 蘇州多久高新企業認證聯系人 2025-12-18
- 山西貿易驗房哪家好 2025-12-18
- 武邑市場教育培訓哪家好 2025-12-18
- 閔行區如何房屋檢測鑒定好處 2025-12-18
- 上海短視頻運營產品介紹 2025-12-18
- 中國臺灣全息光刻機防偽包裝 2025-12-18
- 浙江免疫藥物臨床前評價 2025-12-18